

What Is GraphQL?
In lay terms, GraphQL is a kind of query language and server-side runtime technology widely used for application programming interfaces of APIs that ensure that the client gets the required data. Nothing less or nothing more, and the QL in the name stands for the query language.
Created by Facebook in 2012 while crafting the FB app. GraphQL has a lot of aims and functions, at present it serves as:
- A powerful data-fetching API;
- API interface that’s easy to learn and work with;
- An open-source query language making APIs fast and flexible;
- An effective method to streamline security management for the API;
- A way to give experts the ability to develop APIs with desirable methods;
- A query language that gets along with a given integrated development environment easily and effectively;
- The facility to develop APIs that will function the way the client/end-user wanted or expected;
- An ideal alternative to REST.
GraphQL is here to empower API development and keep the API safety troubles as small as possible. This query language grants complete freedom to the API developers to play on the front foot and shape APIs as per their wish.
How Does It Work?
Designing GraphQL Schema
Created on the server, the base of this schema would be the data on which the app’s UI will be built. For instance, if making the chat application:
type Message {
id: ID!
message: String!
}
type Query {
Messages: [Message]
}
type Mutation {
createMessage(message: String!): Message
}
type Subscription {
messageCreated: Message!
}
Connecting the Resolvers to Available Data Sources
Once the schema is ready, it’s time to write resolve functions for each type. This is done to connect the data to the graph.
The query is sent as a payload to the GraphQL endpoint via POST. The GraphQL engine parses and executes the query against the corresponding resolver. Now, from the result from the resolver, GraphQL picks out the fields that are needed and sends them back to the user. GraphQL uses resolvers to get the data. This data is what the GrpahQL works against the query or mutation to know the action to perform. The query or mutation has a name as the resolver name so the GraphQL engine can match them and perform the necessary action.
The above example of a chat application resolver implemented in GoLang with Redis can look like this:
package graph
import (
"context"
"errors"
"golang-graphql-subscriptions/graph/generated"
"golang-graphql-subscriptions/graph/model"
"log"
"github.com/go-redis/redis"
"github.com/thanhpk/randstr"
)
func (r *mutationResolver) CreateMessage(ctx context.Context, message string) (*model.Message, error) {
m := model.Message{
Message: message,
}
r.RedisClient.XAdd(&redis.XAddArgs{
Stream: "room",
ID: "*",
Values: map[string]interface{}{
"message": m.Message,
},
})
return &m, nil
}
func (r *queryResolver) Messages(ctx context.Context)
([]*model.Message, error) {
streams, err := r.RedisClient.XRead(&redis.XReadArgs{
Streams: []string{"room", "0"},
}).Result()
if !errors.Is(err, nil) {
return nil, err
}
stream := streams[0]
ms := make([]*model.Message, len(stream.Messages))
for i, v := range stream.Messages {
ms[i] = &model.Message{
ID: v.ID,
Message: v.Values["message"].(string),
}
}
return ms, nil
}
func (r *subscriptionResolver) MessageCreated(ctx context.Context) (<-
chan *model.Message, error) {
token := randstr.Hex(16)
mc := make(chan *model.Message, 1)
r.mutex.Lock()
r.messageChannels[token] = mc
r.mutex.Unlock()
go func() {
<-ctx.Done()
r.mutex.Lock()
delete(r.messageChannels, token)
r.mutex.Unlock()
log.Println("Deleted")
}()
log.Println("Subscription: message created")
return mc, nil
}
// Mutation returns generated.MutationResolver implementation.
func (r *Resolver) Mutation() generated.MutationResolver { return &mutationResolver{r} }
// Query returns generated.QueryResolver implementation.
func (r *Resolver) Query() generated.QueryResolver { return &queryResolver{r} }
// Subscription returns generated.SubscriptionResolver implementation.
func (r *Resolver) Subscription() generated.SubscriptionResolver { return &subscriptionResolver{r} }
type mutationResolver struct{ *Resolver }
type queryResolver struct{ *Resolver }
type subscriptionResolver struct{ *Resolver }
Write a Query for the Things You Want
Lastly, you start writing your query. You can specify the details you need to fetch, which works to the point. At this stage, using a GraphQL client library such as Apollo Client is highly suggested as it makes query writing an effortless task.
{
messages{
id
message
}
}
Queries
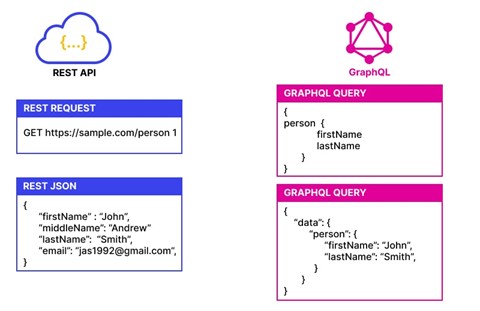
A GraphQL query is used to read or fetch values. The operation is a simple string that a GraphQL server can parse and respond to with data in a specific format. JSON is usually the popular response format for mobile and web applications.
The syntax to define a query is as follows:
//syntax 1
query query_name{ someField }
//syntax 2
{ someField }
Mutations
Most discussions of GraphQL focus on data fetching. Still, any complete data platform needs a way to modify server-side data as well.
In REST, any request might end up causing some side-effects on the server, but by convention, it’s suggested that one doesn’t use GET requests to modify data. GraphQL is similar – technically, any query could be implemented to cause a data write. However, it’s helpful to establish a convention that any operations that cause write should be sent explicitly via a mutation.
Like in queries, if the mutation field returns an object type, you can ask for nested fields. This can be useful for fetching the new state of an object after an update.
type Mutation {
createEntity(entityId:ID,entityName:String,entitySurname:String):String
}
Subscriptions
GraphQL employs Subscriptions to deliver real-time updates from the GraphQL server to the subscribed clients. It is like using Socket.io to set up real-time communication from the server to the frontend. Here, GraphQL has it inbuilt into its functionality.
GraphQL subscriptions are made majorly to listen to when data is created on the server, when data is updated when data is deleted, and when data is read via query. The event to emitted is dependent on what the dev wants. The events are pushed from the server to the subscribing clients.
type Subscription {
commentAdded(postID: ID!): Comment
}
Client-side:
const COMMENTS_SUBSCRIPTION = gql`
subscription OnCommentAdded($postID: ID!) {
commentAdded(postID: $postID) {
id
content
}
}
`;
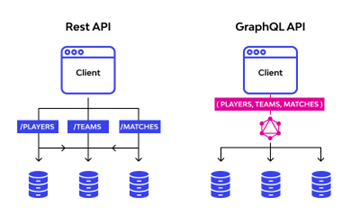
REST vs. GraphQL
GraphQL has a specific endpoint or resource for the entire block of data. REST uses different data endpoints.
GraphQL works around schema, queries, and resolvers that allow one to work with a specific piece of data. On the other hand, what you ask for will reach you by passing from different REST APIs in the case of REST.
REST is a type of architecture pattern, while GraphQL is mainly a query language.
API development is faster in GraphQL when compared to REST.
Advantages and Disadvantages of REST
REST has been here for a very long time and is still popular. This popularity is not without reason. Users are bound to experience some notable benefits like:
- Easy development of complex projects
- Software/application scalability is possible
- Seamless adaptability
- Customized API development is possible
- Processing without asking for routing information
- Data migration from one server to another is without any hassles
Despite the promising benefits, it comes with significant drawbacks that include:
- No maintenance of client-server communication state
- Separate API calls must be made for retrieving data from different endpoints
- Data searching facilities are not impressive
- Guidance isn’t offered for using framework or tool
- No query validation is possible
- No changes in APIs are promoted
Advantages and Disadvantages of GraphQL
Be ready to experience some of the notable benefits like:
- Easy and viable caching and batching of query
- Auto-documentation sync with API
- Product-centric approach
- Numerous data fetching with one API call
- Query execution as per the system’s context
- Multiple database handling
- A query that is easy-to-understand
- Freedom to decide compatible functions and predefining their functioning
However, it’s not always a lucrative deal as it features certain drawbacks such as:
- Ineptitude in proposing comfortable design patterns when complex app designing is concerned
- Small application development becomes exhaustive
- It’s not a viable option for using complicated queries
- A single endpoint that makes API entry tedious.
- No API versioning supported
A comparative table:
| REST | GraphQL |
| It provides guidelines for key API designing principles that are required for web application development | It is a technology that server uses to execute queries with pre-present data |
| Based on the serve-driven architecture | Based on the client-driven architecture |
| Has earned a name and fame and has huge database | It’s a relatively new technology and will take time to come into mainstream |
| Development is a time-consuming process | Speeds up the development process |
| Not very tough to learn and offers various reference material | GraphQL is tough to learn and not much community support is offered |
| Performance consistency isn’t offered across the platform | GraphQL is a highly quality-consistent technology |
| Weakly typed | Strongly typed theology |
| Multiple API endpoints | Unified API endpoint |
| Object identity is associated with the endpoint | Object is independent |
| No need for metadata | Metadata is crucial for query verification |
| API scalability and updates are easy | Added efforts and technology are required for API upgrade and customization |
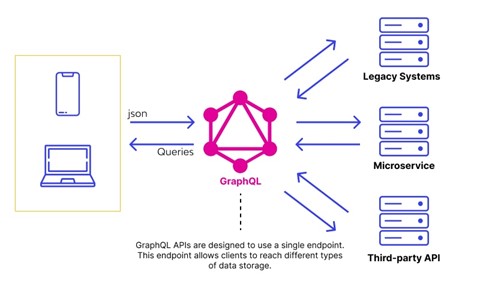
When Should You Use GraphQL?
GraphQL is an excellent solution to a unique problem around building and consuming APIs. When used as designed, it can be an ideal tool for the use cases described below.
Data fetching control
GraphQL was designed to allow the client to ask for only the needed data. While the server might be able to deliver more data to the client for a single request, it would only send the data requested by the client. If you want the client to control the type and amount of data it needs, GraphQL would be ideal for your project.
Using multiple data sources
GraphQL simplifies the task of aggregating data from multiple sources or APIs and then resolving the data to the client in a single API call. On the other hand, API technologies like REST would require multiple HTTP calls to access data from multiple sources.
Alleviating bandwidth concerns
Bandwidth is a problem for small devices like mobile phones, smartwatches, and IoT devices that cannot handle large amounts of data. Using GraphQL helps minimize this issue. Because GraphQL allows the client to specify what data it needs, the server doesn’t send excess data, which could reduce the app’s performance when bandwidth is limited.
Rapid prototyping
GraphQL exposes a single endpoint that allows you to access multiple resources. In addition, resources are not exposed according to the views that you have inside your app. For example, if your UI changes require either more or less data, it doesn’t have an impact nor require changes on the server.
MORE RESOURCES:
https://graphql.org/
https://hasura.io/
https://docs.github.com/en/graphql
https://www.graphql.com/
https://www.wallarm.com/